
负责任的发展生成式人工智能的挑战及应对路径[人工智能][其他]
發(fā)表于:2024/7/29 下午4:57:00
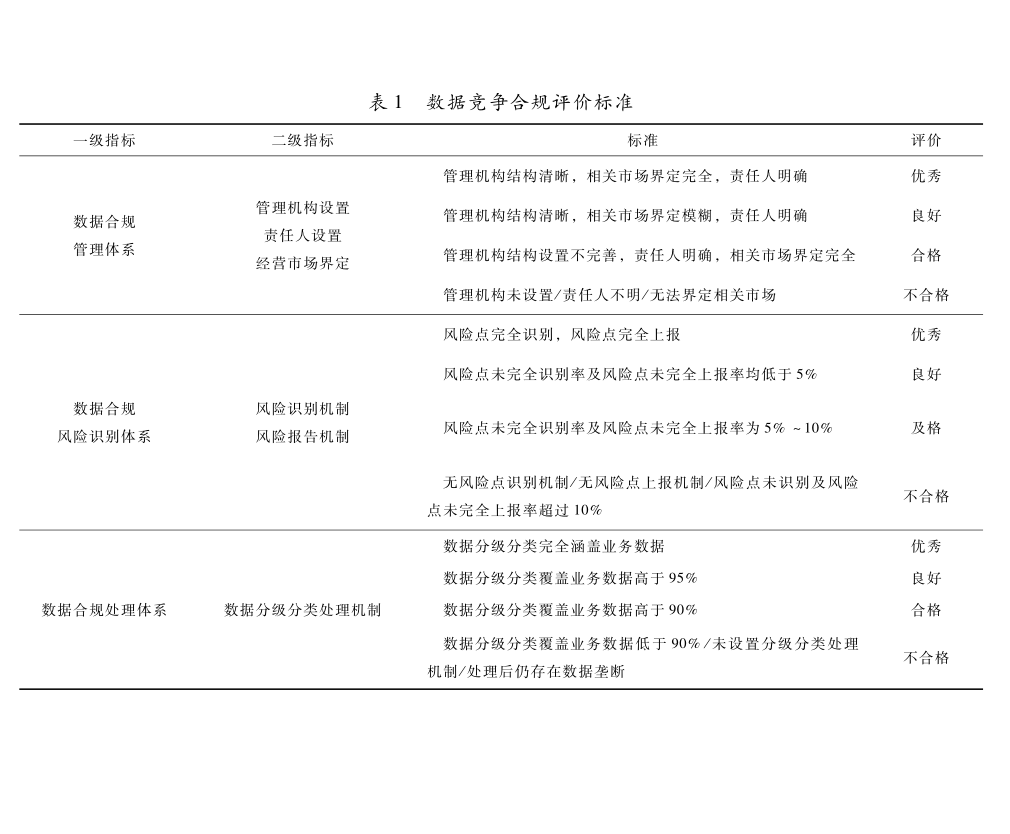
数字经济下平台数据垄断合规的理据与路径[其他][其他]
發(fā)表于:2024/7/29 下午4:41:00
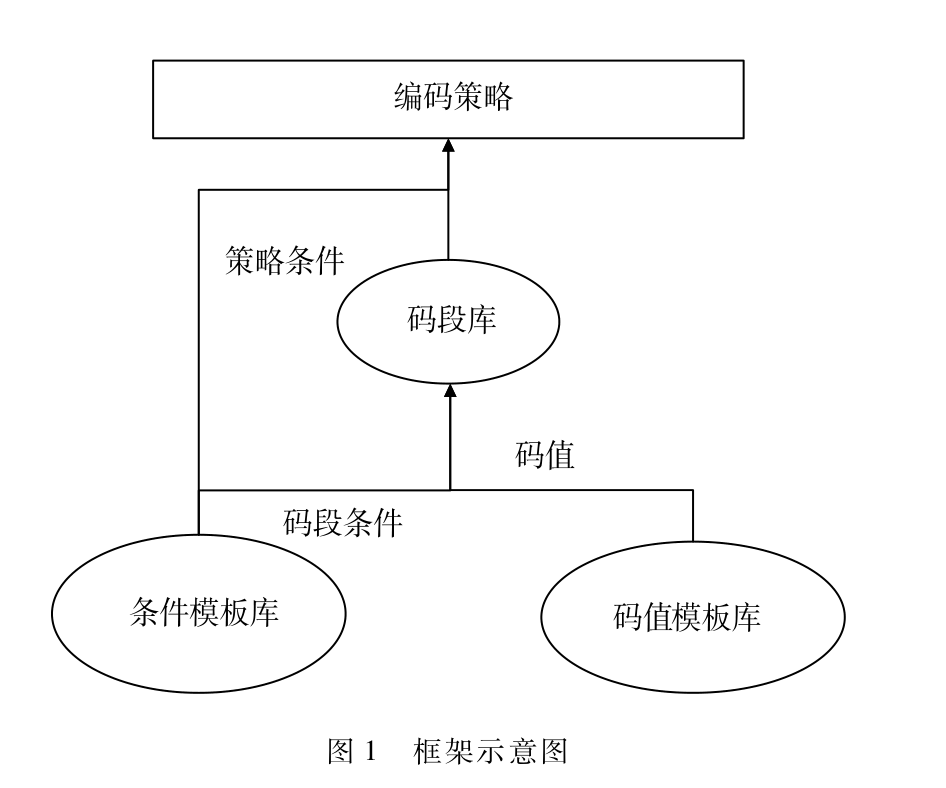
基于条件设置的主数据编码规则应用与研究[其他][其他]
發(fā)表于:2024/7/29 下午4:28:00

俄罗斯人工智能监管政策分析:框架、特征及启示[人工智能][信息安全]
發(fā)表于:2024/7/29 下午3:57:00

基于Boosting集成学习的风险URL检测研究[通信与网络][信息安全]
發(fā)表于:2024/7/29 下午3:40:00

基于交易时间衰减的以太坊恶意地址检测方法[通信与网络][信息安全]
發(fā)表于:2024/7/29 下午3:26:00


基于生成对抗网络的工控协议模糊测试研究[通信与网络][数据中心]
發(fā)表于:2024/7/29 下午3:00:00

云化工业软件安全风险与应对策略研究[通信与网络][信息安全]
發(fā)表于:2024/7/29 下午2:50:00