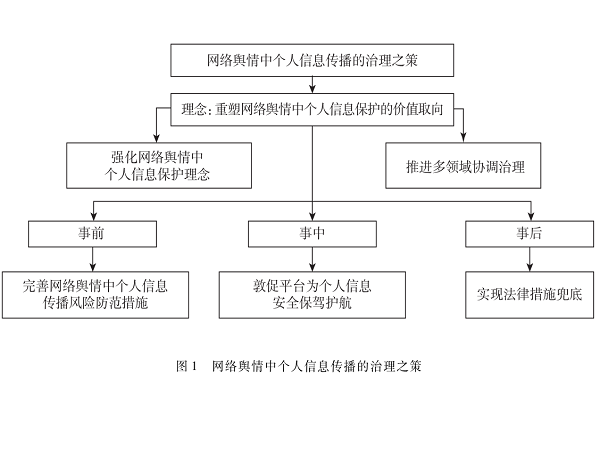
网络舆情中个人信息传播的成因、风险透视及治理[其他][其他]
發(fā)表于:2025/10/15 下午4:18:11
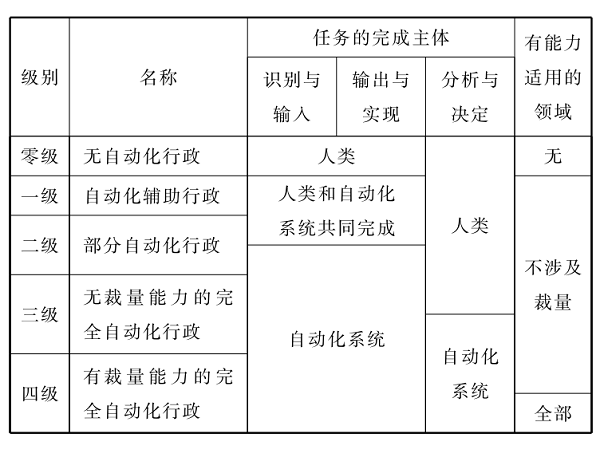
正当程序框架下的算法行政:挑战纾解与规制重构[其他][其他]
發(fā)表于:2025/10/15 下午4:09:01
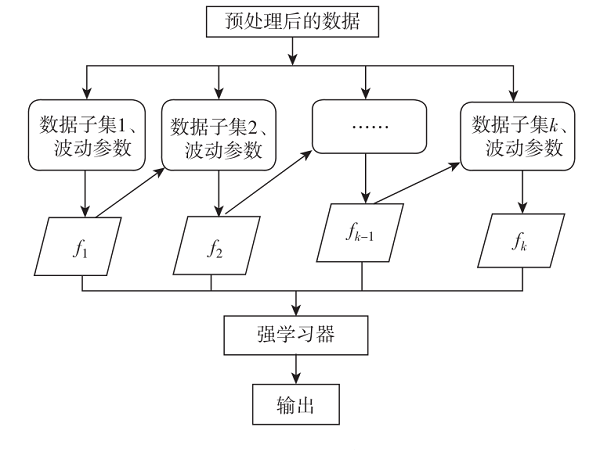
HF和波动参数辅助的优化XGBoost室内定位方法[通信与网络][通信网络]
發(fā)表于:2025/10/15 下午4:01:12
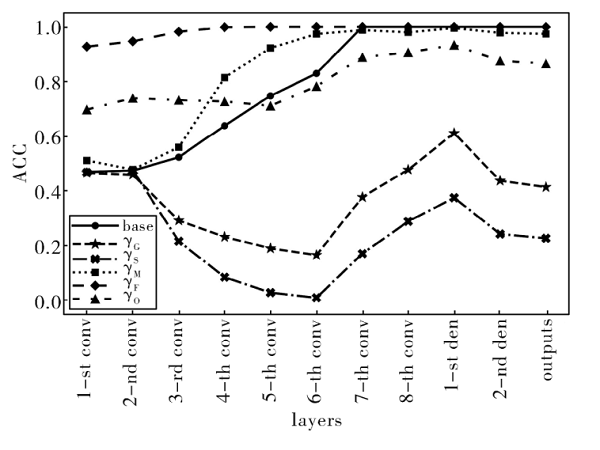
可解释的深度网络抗噪音干扰性逐层评估方法[其他][其他]
發(fā)表于:2025/10/15 下午3:30:12
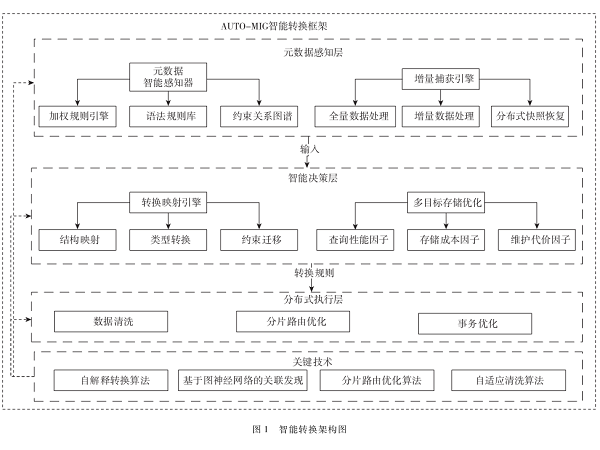
大规模异构数据迁移的自适应清洗与智能转换框架[其他][其他]
發(fā)表于:2025/10/15 下午3:17:00
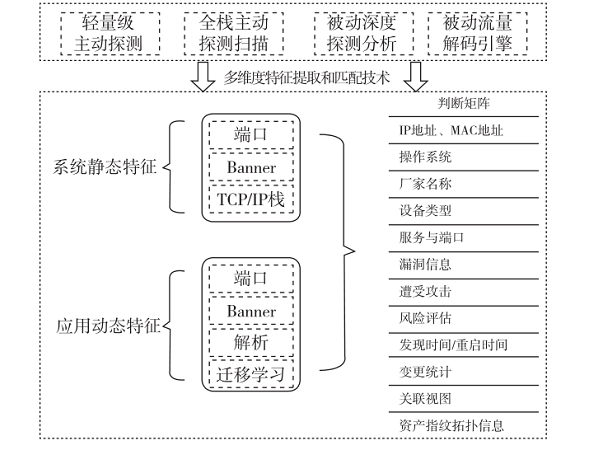
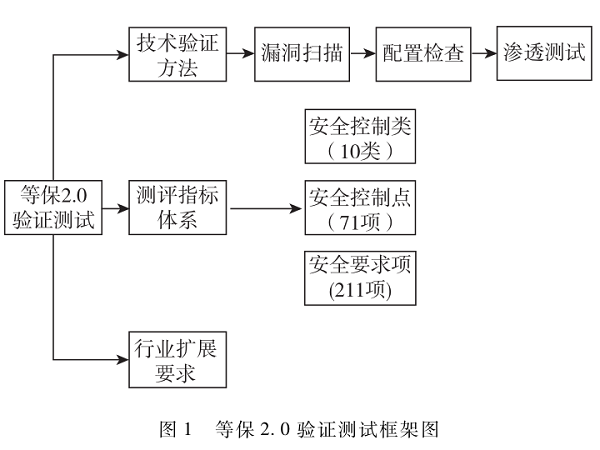
基于等保2.0验证测试与ATT&CK攻击矩阵的融合实践[通信与网络][信息安全]
發(fā)表于:2025/10/14 下午5:14:56
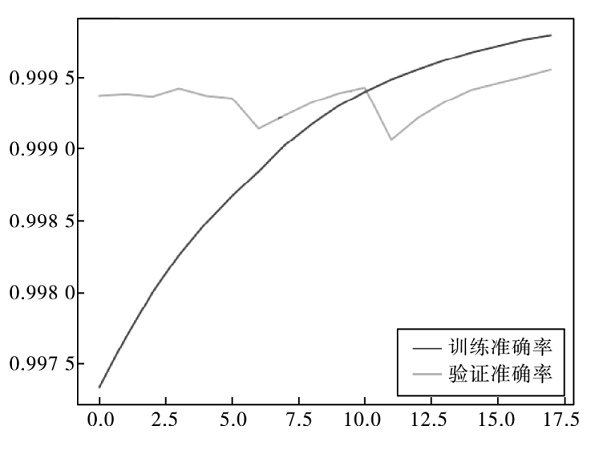
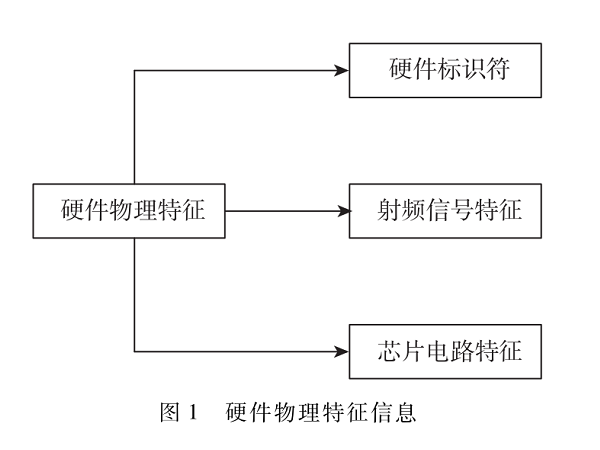
一种融合多维信息的电力物联网设备指纹识别技术[通信与网络][智能电网]
發(fā)表于:2025/10/14 下午4:55:00