
运用SAD算法降低FPGA资源利用率
新加坡南洋理工大学 赛灵思供稿
Sharad Sinha 高性能嵌入式系统中心
摘要: 资源共享是一种在保持功能性的同时减少面积或资源占用率的传统方法。其中包括通过将一个以上的运算映射到一个运算器,实现算术运算器(如加法器、乘法器等)的共享。例如,共享后3个加法器可执行6个而不是3个加运算,使用的加法器数量减少了一半,从而减少了资源占用率。通过Xilinx ISE软件,可以在合成属性对话框中开启相应开关(resource sharing)后进行资源共享。当在一个if-else程序块(图1)或case-endcase程序块(图2)中描述互斥的任务后,这些工具能检测并实施资源共享。
Abstract:
Key words :
基于FPGA的設(shè)計(jì),需要仔細(xì)檢查設(shè)計(jì)所占用的面積以及實(shí)施后的時(shí)序性能,以確保設(shè)計(jì)適合目標(biāo)器件,并滿足其時(shí)序或吞吐力要求。在基于FPGA的商用設(shè)計(jì)中,設(shè)計(jì)師通常會(huì)將查找表(LUT)的資源占用率上限設(shè)置為80%左右,以便為未來(lái)升級(jí)和功能改進(jìn)留有資源,并可讓時(shí)序收斂更容易。余下約20%的空閑LUT留下了空余的布線資源,有助于滿足嚴(yán)格的時(shí)序約束。
在設(shè)計(jì)中,F(xiàn)PGA結(jié)構(gòu)里嵌入的邏輯越多,占用的布線資源就會(huì)越多。綜合工具或許能將更多邏輯成功地映射到LUT和其它資源,但很可能無(wú)法在二者之間布線。因?yàn)楝F(xiàn)有的邏輯已經(jīng)顯著提高了互連使用率,已經(jīng)沒(méi)有端到端路徑來(lái)路由更多連接的信號(hào)。即使可能存在布線空間,布線器也無(wú)法對(duì)其建立端到端連接。因此,雖然有可用的LUT資源,但設(shè)計(jì)受到了“互連限制”,所以有可能無(wú)法進(jìn)行擴(kuò)展。
減少設(shè)計(jì)面積還具有經(jīng)濟(jì)意義。在符合應(yīng)用要求的情況下,F(xiàn)PGA器件越小,設(shè)計(jì)和生產(chǎn)成本則越低。當(dāng)然,如果有以太網(wǎng)模塊、嵌入式處理器或收發(fā)器等特殊需求,就需要選擇能通過(guò)硬IP或軟IP支持這些模塊的FPGA。不過(guò)在設(shè)計(jì)中,減少其它部件的使用面積,仍有助于從支持這類特殊模塊的FPGA系列中進(jìn)行選擇。
資源共享
資源共享是一種在保持功能性的同時(shí)減少面積或資源占用率的傳統(tǒng)方法。其中包括通過(guò)將一個(gè)以上的運(yùn)算映射到一個(gè)運(yùn)算器,實(shí)現(xiàn)算術(shù)運(yùn)算器(如加法器、乘法器等)的共享。例如,共享后3個(gè)加法器可執(zhí)行6個(gè)而不是3個(gè)加運(yùn)算,使用的加法器數(shù)量減少了一半,從而減少了資源占用率。通過(guò)Xilinx ISE軟件,可以在合成屬性對(duì)話框中開啟相應(yīng)開關(guān)(resource sharing)后進(jìn)行資源共享。當(dāng)在一個(gè)if-else程序塊(圖1)或case-endcase程序塊(圖2)中描述互斥的任務(wù)后,這些工具能檢測(cè)并實(shí)施資源共享。

圖1:if-else程序塊

圖2:case-endcase程序塊
如圖所示,這些任務(wù)都是互斥的。因此,啟用資源共享后,8個(gè)加運(yùn)算可以共享兩個(gè)加號(hào)。這類資源共享依賴于鑒別寄存器傳輸級(jí)(RTL)設(shè)計(jì)中可能存在的互斥任務(wù)。然而,如果不存在互斥任務(wù),資源應(yīng)該如何共享?這樣做又有何利弊?為了回答這個(gè)問(wèn)題,下面將從更高層次的抽象概念對(duì)資源共享進(jìn)行深入研究。
比RTL更勝一籌
“更高層次的抽象概念”是指比RTL更高級(jí)別的設(shè)計(jì)描述,可在RTL準(zhǔn)備好前對(duì)要實(shí)施的應(yīng)用進(jìn)行分析。如果可以通過(guò)分析應(yīng)用來(lái)了解其內(nèi)在并行性,則在RTL設(shè)計(jì)中也可以這樣做。此外,對(duì)應(yīng)用的數(shù)據(jù)流程圖進(jìn)行分析有助于設(shè)計(jì)資源共享的實(shí)施。
數(shù)據(jù)流程圖能提供關(guān)于應(yīng)用數(shù)據(jù)流的信息。數(shù)據(jù)從一個(gè)運(yùn)算流向另一個(gè)運(yùn)算,因此在運(yùn)算之間可能存在著數(shù)據(jù)依賴關(guān)系。不相互依賴的運(yùn)算可以并行執(zhí)行。不過(guò)并行執(zhí)行幾乎總是造成很高的資源占用率,而目標(biāo)是降低資源占用率,所以暫不討論并行執(zhí)行這種模式。
下面將以絕對(duì)差值和(SAD)算法為例,介紹如何從比RTL更高層次的抽象層分析資源共享,讓資源占用率比依賴RTL設(shè)計(jì)中的互斥任務(wù)的方法更低。
SAD是MPEG-4解碼器動(dòng)作估計(jì)部分中的一種重要算法,也能用于物體識(shí)別。在這種以像素為基礎(chǔ)的方法中,圖像區(qū)塊中每個(gè)像素的值都與另一幅圖像中相應(yīng)像素的值相減,以確定該圖像的哪些部分從一幀移到了另一幀。如果圖像區(qū)塊大小為4x4,則最后會(huì)將全部16個(gè)絕對(duì)差值相加。在開源xvid解碼器的sad.c文件末尾有代碼示例。
圖3顯示了用這一算法處理一個(gè)4x4圖像區(qū)塊時(shí)的數(shù)據(jù)流圖(DFG)。這些減法運(yùn)算可以并行,因?yàn)槠渲械臏p法運(yùn)算不依賴于其它任何減法運(yùn)算。但由于目的在于降低資源占用率,所以并不采用并行執(zhí)行模式。而是采用一種稱為基于擴(kuò)展兼容路徑(ECPB)硬件綁定的資源分配和綁定算法。
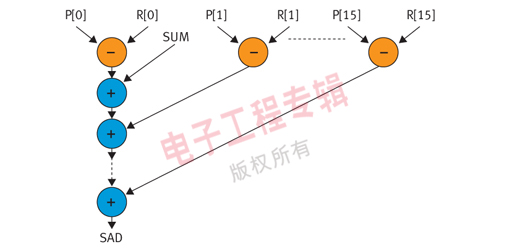
圖3:SAD算法的數(shù)據(jù)流圖
資源的分配和綁定主要是指為DFG中的運(yùn)算分配加號(hào)、乘號(hào)等資源,然后將這些資源綁定到運(yùn)算,以便降低器件的資源占用率、提高最大時(shí)鐘頻率,或同時(shí)實(shí)現(xiàn)兩者。原則是在最終設(shè)計(jì)符合功能限制的前提下縮小面積。此算法可以檢測(cè)已調(diào)度的DFG(即其運(yùn)算已在不同步驟或時(shí)鐘周期中進(jìn)行了調(diào)度)中各運(yùn)算間流程的依存關(guān)系,并分析出運(yùn)算內(nèi)部(intra-operation)流程的依存關(guān)系。
此算法將可并行的運(yùn)算調(diào)度在同一時(shí)間步驟中,并將需要依賴于其它運(yùn)算數(shù)據(jù)的運(yùn)算調(diào)度到不同的時(shí)間步驟中。它為已調(diào)度DFG中的每種運(yùn)算都建立了一個(gè)加權(quán)的有序相容圖(WOCG)。因此,減法運(yùn)算有一個(gè)WOCG,加法運(yùn)算則有另外一個(gè)WOCG。這種方法使用了加權(quán)關(guān)系Wij =1+α×Fij +β×Nij +y ×Rij來(lái)為WOCG中的各邊(edges)分配權(quán)重。在這里,Wij即同類型的i和j運(yùn)算之間的權(quán)重值。Fij是流程依存關(guān)系的權(quán)重值,而Nij是運(yùn)算i和j之間的共模輸入數(shù)量。如果運(yùn)算i和j的輸出結(jié)果可以存入同一個(gè)寄存器,則Rji的值為1,否則即為0。在本例中,將調(diào)整參數(shù)數(shù)α、β和γ的值分別設(shè)為1、1和2。
接下來(lái)的步驟是用最長(zhǎng)路徑算法找出WOCG中使用的最長(zhǎng)路徑。該最長(zhǎng)路徑中的全部運(yùn)算都被映射到同一運(yùn)算器。將綁定運(yùn)算從WOCG中移除后,重復(fù)最長(zhǎng)路徑和映射流程,直到處理完所有WOCG。由于這種算法會(huì)將多個(gè)運(yùn)算映射到同一資源或運(yùn)算器,所以運(yùn)算器的容量相當(dāng)大,足以滿足最大規(guī)模的運(yùn)算。在實(shí)施SAD方法的例子中,8位數(shù)據(jù)(灰度圖像)處理了全部減法運(yùn)算,因此,減法運(yùn)算器的輸入寬度是8位。我們將負(fù)責(zé)迭代計(jì)算SAD和的累加運(yùn)算器位寬設(shè)定為23位和8位。
圖4顯示了實(shí)施的SAD算法的數(shù)據(jù)路徑。在這個(gè)設(shè)計(jì)中只使用了一個(gè)減法器和一個(gè)加法器/累加器。各個(gè)運(yùn)算之間有著非常多的資源共享。如果直接在RTL行為層描述設(shè)計(jì),這種資源共享將不可能實(shí)現(xiàn),因?yàn)镾AD算法中不存在互斥的任務(wù)。生成這個(gè)數(shù)據(jù)路徑后,可用加法器、減法器和乘法器模塊分層實(shí)施設(shè)計(jì)。這一包含模塊實(shí)例化的實(shí)施方法比行為化的方法結(jié)構(gòu)更為明晰,并且與后者的數(shù)據(jù)路徑非常相似。

圖4:采用SAD算法的數(shù)據(jù)路徑
在以數(shù)據(jù)為主導(dǎo)的大型應(yīng)用中,在更高層次進(jìn)行此類預(yù)處理有助于降低資源占用率。此外,這種方法也很容易實(shí)現(xiàn)自動(dòng)化。
為了比較ECPB算法生成的數(shù)據(jù)路徑獲得的物理綜合結(jié)果,我們還進(jìn)行了一次完全并行的實(shí)施,兩次與圖4中的數(shù)據(jù)路徑相同的實(shí)施。后兩次是無(wú)層次的行為設(shè)計(jì),最終RTL描述沒(méi)有分層,包含引起復(fù)用的“強(qiáng)制”互斥任務(wù)。“強(qiáng)制”是指實(shí)施與圖4中相同的數(shù)據(jù)路徑,但采用了包含互斥任務(wù)的行為描述。其中一種設(shè)計(jì)具有if-else結(jié)構(gòu),另一種具有case-endcase結(jié)構(gòu)。表1展示了使用Xilinx ISE 12.2(M.63C)軟件默認(rèn)設(shè)置、以Virtex-4XC4VFX140-11FF1517為目標(biāo)器件,且沒(méi)有時(shí)間限制的情況下獲得的后時(shí)序(post-place-and-route)結(jié)果。內(nèi)部寄存器也進(jìn)行了相應(yīng)的初始化,所有實(shí)施過(guò)程中都沒(méi)有重置。
在這個(gè)表格中,RS和NRS分別表示在Xilinx ISE已啟用或禁用資源共享的情況。設(shè)計(jì)方案I和II是因?yàn)椴煌木C合工具可以從不同格式的HDL代碼(if-else、case-end-case)中推論出不同的復(fù)用類型。時(shí)鐘周期沒(méi)有考慮抖動(dòng)的情況,所以應(yīng)該根據(jù)時(shí)鐘源規(guī)范降低一定數(shù)量。同時(shí),任何方案都未使用預(yù)處理寄存器進(jìn)行輸入。
資源節(jié)省
如表所示, LUT消耗顯著降低,最高可達(dá)56%,最少也有20%。不過(guò),資源共享與完全并行的實(shí)施方法不同,后者的數(shù)據(jù)樣本大體上在每個(gè)時(shí)鐘周期都可用,而資源共享使用數(shù)據(jù)樣本處理的過(guò)程會(huì)有一些限制。由于資源被共享,只有在前一份數(shù)據(jù)樣本部分或完全處理后,才能處理新的數(shù)據(jù)樣本。在ECPB實(shí)施中,新的P和R系列值至少要在16個(gè)時(shí)鐘周期后才能使用。
雖然這一技術(shù)不是任何地方都適用,但它非常適合運(yùn)用在類似采樣率(sample rate)的應(yīng)用中。例如,ECPB設(shè)計(jì)能夠輕松地在1.016毫秒內(nèi)處理一個(gè)尺寸為720x576的DV-PAL幀,而不會(huì)對(duì)25幀/秒的PAL幀速率產(chǎn)生任何影響。
表1:結(jié)果對(duì)比(RS和NRS分別表示已啟用或禁用資源共享的情況)

此內(nèi)容為AET網(wǎng)站原創(chuàng),未經(jīng)授權(quán)禁止轉(zhuǎn)載。